Scrape this, not that: using rvest to build a database of Champagne
So you want to scrape some information from a website? if you’re reading this, I assuming you have a basic understanding of what “scraping” is, so I won’t get into the weeds on the theory but more on the application in R using just a few packages: rvest, dplyr and stringr.
Before I start, let me point you to the rvest documentation for installation and release information .
Although the documentation is quite comprehensive, I want to go over some very basic HTML definitions that will make your experience go a lot smoother.
- Elements: These are your main “tags” such as
<h1> Heading 1 </h1>or<p> Wine is life.</p>. The basic structure of a page is:
<html>
<body>
#body of your page
</body>
</html>The rvest::html_nodes() function is what you will use to specify which elements, specifically the CSS selector. For example, calling html_nodes(myhtmldoc, ".CSS-selector span") %>% html_text() will retrieve the text associated with the specified <span> tag. If this doesn’t make sense right away, don’t worry you’ll see an example below.
- Attributes: These provide additional information for the element, such as an image source (
src) or a link’s path (href). These are usually displayed as key/value pairs, i.e.width="500". You will uservest::html_attr("YOUR ATTRIBUTE")if you need to get specific details from an attribute.
Finally, it’s a good idea to familiarize yourself with the “Inspect” feature from your browser. This allows your to see the breakdown of any web-page your viewing. This is where you will also find the names for the elements and attributes you want to scrape!
(pro tip: use the "select element feature to jump directly to the element you’re looking for)
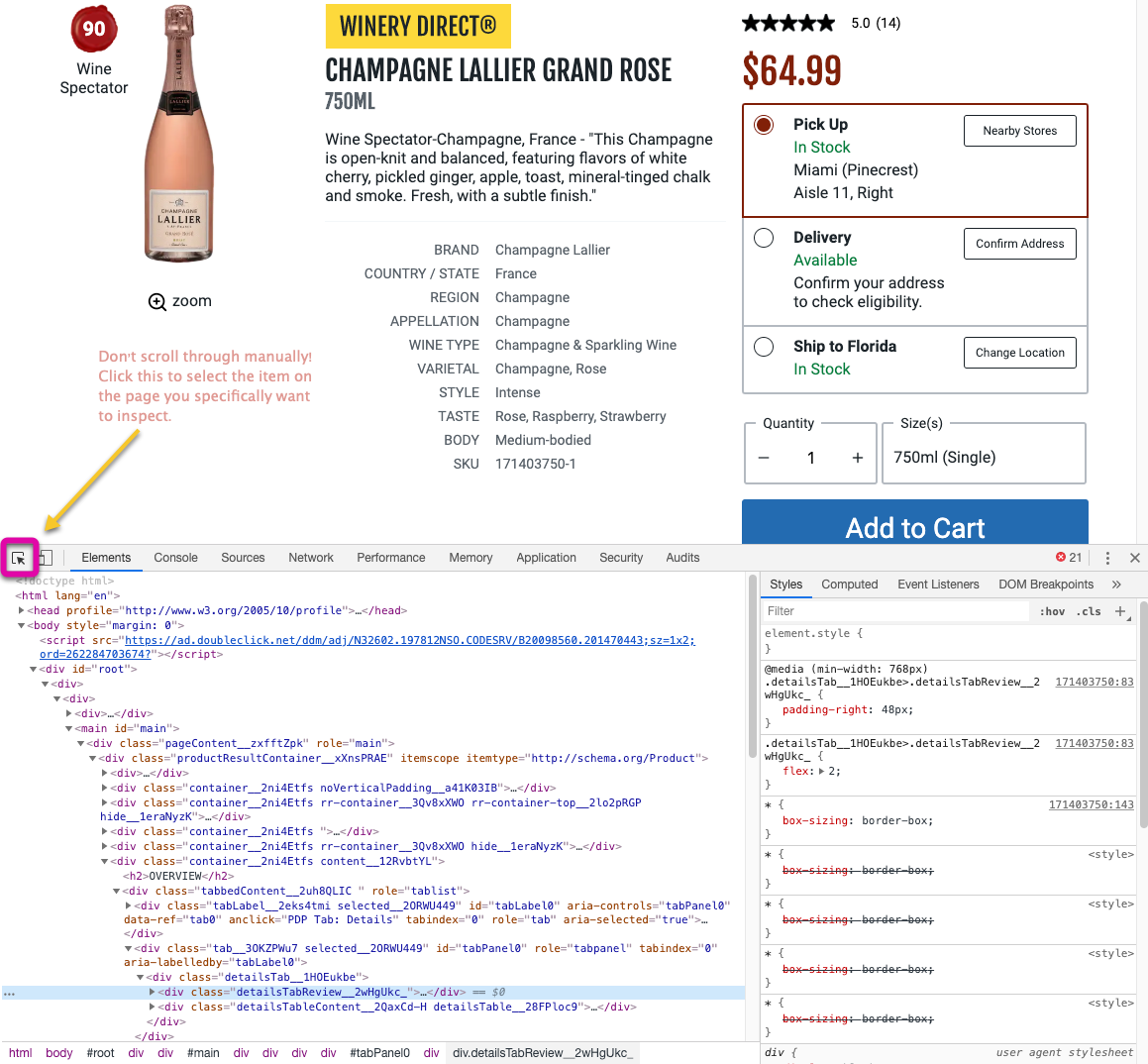
Note: rvest cannot handle JS, it only reads the HTML before JS loaded so some objects may not be possible to scrape with this package. However, if you have the inspect console open in your browser, go to the “Network” tab, refresh the page and try looking for a GET request made to an API (api may be in the URL). This is data stored in a JSON file which can be read using jsonlite::fromJSON()
Don’t get intimidated. It’s quite simple. Here, let me show you:
Scrape the details of a specific wine
I want to know the details of this pretty Champagne Rose from Lallier
library(dplyr)
library(rvest)
path <- "https://www.totalwine.com/wine/champagne-sparkling-wine/champagne/rose/champagne-lallier-grand-rose/p/171403750?"
#details table - brand, country/state, region, wine type, varietal, style, taste, body, sku
details <- read_html(path) %>%
html_nodes(".detailsTableLabel__kj9FI2Mq, .detailsTableText__1SvcRdYn") %>% #the two element names of the details table separated by a ","
html_text() #extract the textThe above code chunk returns a character vector of length 40. Well, that’s not really helpful. It would be nice to clean this up into a nice tidy format. We are going to make a it a wide table in preparation of row-binding more wines in a subsequent step ;)
#convert the table to a dataframe and make it wide with clean names
details_df <- tibble(label = details[seq(1,18,2)], #the label of the data piece is every other odd string in the vector
text = details[seq(2,18,2)]) %>% #the data piece itself is every other even string in the vector
tidyr::pivot_wider(names_from = label, values_from = text) %>% #make the labels the colnames
rename_with(.cols = everything(), .fn = janitor::make_clean_names) #remove any slashes, dash or other bad characters, make lower, and snake_caseSee, that wasn’t so bad! Now, we don’t want this information for just one wine. What if we wanted to collect this information on all Champagnes offered through Total Wine? Simple, my friend - we’ll wrap it in a function!
First we need to get the paths for all Champagnes by going to totalwine.com and extract the particular element that corresponds to sparkling wines - specifically Champagnes.
This is where a little manual searching is required (read easier). After going to the site, selecting Wine > Champagne & Sparkling Wine we are left with 706 results. But, we are interested in Champagnes so that will require clicking on the “Champagne” filter under “Varietal & Type”. I want you to notice how the path in the URL bar changes - that’s exactly what you want. Pages whose paths do not change when any filtering/action is done are called single page applications (SAP) and are not very easy to scrape. Thankfully, this doesn’t apply to us. Thankfully, it seems like Total Wine has a pretty solid database where each chunk of the path is another table being indexed.
Filtering, brought us down to 235 results. This is more than one page so our first step will be to extract all the paths for each of the 235 Champagnes.
#for simplicity, I've expanded the "items per page" option from 24(default) to 120
#page 1 out of 2 -- path not the same for page 2
wine_paths_pg1 <- read_html("https://www.totalwine.com/wine/champagne-sparkling-wine/c/000005?viewall=true&pageSize=120&varietaltype=Champagne") %>%
html_nodes(".productImg__3fOOgAmO a") %>% #the a is to indicate we want specifically an <a> tag - for hyperlinks
html_attr("href") %>%
tibble("path" = .)
wine_paths_pg2 <- read_html("https://www.totalwine.com/wine/champagne-sparkling-wine/c/000005?viewall=true&page=2&pageSize=120&varietaltype=Champagne") %>%
html_nodes(".productImg__3fOOgAmO a") %>% #the a is to indicate we want specifically an <a> tag - for hyperlinks
html_attr("href") %>%
tibble("path" = .)
#bind the 1st page to 2nd page
wine_paths <- bind_rows(wine_paths_pg1, wine_paths_pg2) #this returns 197/235 paths...this is really good as some requests may return nullNow let’s get those details!
We will take the code chunk up above and wrap it in a function but use the path as the argument
#details table - brand, country/state, region, wine type, varietal, style, taste, body, sku
get_details <- function(path){
details <- read_html(paste0("https://www.totalwine.com",path)) %>% #paste the the first part of the URL to the Champagne specific path
html_nodes(".detailsTableLabel__kj9FI2Mq, .detailsTableText__1SvcRdYn") %>%
html_text()
#convert the table to a dataframe and make it wide with clean names
details_df <- tibble(label = details[seq(1,18,2)],
text = details[seq(2,18,2)]) %>%
tidyr::pivot_wider(names_from = label, values_from = text) %>%
rename_with(.cols = everything(), .fn = janitor::make_clean_names)
}
champagne_df <- purrr::map_dfr(wine_paths$path, get_details)Et voila! Une belle base de donnees de Champagne! Sante!